A Tour of C++
| Created | |
|---|---|
| Class | C++ |
| About | C++ 学习笔记,含C++ 20 新特性、学习资料 |
Chapter 1: The Basics
When we want a type of specific size, use STL alias, such as int32_t
To make long literals more readable for humans, use ‘ as digit separator. pi is 3.14159’26535’89793
int i1 = 7.8; // (narrowing conversion - i1 = 7), a price to pay for C compatibility
int i2{7.8}; // error: floating-point to integer conversionScope and Lifetime
local scope: block scope, inside function/lambda.
class scope: member of class, outside function/lambda/enum class
namespace scope: namespace outside of any function, lambda, class or enum.
global name: global namespace
Constants
const: used to specify interfaces so that data can be passed without being modified. Compiler enforces the promise made by const. Value of const may be calculated at run-time.
constexpr: to be evaluated at compile-time. Used to specify constants, placement of data in read-only memory, and for performance. Value of constexpr must be calculated by compiler.
consteval: when we want a function to be used only for evaluation at compile time, we declare it consteval rather than constexpr.
constexpr double square(double x) { return x*x; }
constexpr double max1 = 1.4*square(17); // OK: 1.4*square(17) is constant expression
constexpr double max2 = 1.4*square(var); // error: var is not constant, square(var) is not constexpr
const double max3 = 1.4*square(var); // OK: 1.4*square(var) being evaluated at run time
consteval double square2(double x) { return x*x; }
constexpr double max4 = 1.4*square(17); // OK: 1.4*square(17) is constant expression
const double max5 = 1.4*square(var); // Error: var is not constant
Initialization
For almost all types, the effect of reading from or writing to an uninitialized variable is undefined.
int x = 7;
int& r{x}; // bind r to x (reference only can bind once)
r = 10; // assign r to 10, x also equals 10
int& r2; // error: uninitialized refernce
r2 = 99; // assigning 99 to some unspecified memory location could lead to bad results/crash
Chapter 2: User-Defined Types
There is no difference between class and struct. Struct is simply a class with members public by default.
Enumerations
enum class Color { red, blue, green };
enum class Traffic_light { green, yellow, red };
Color x1 = red; // error: which red?
auto x2 = Color::red; // OK: Color::red is Color
Color x3 = 2; // initialization error: Color is not int
Color x4{2}; // OK- since enum underlying type by default is int
int i = int(Color::red); // OK: explicitly convert enum value to its underlying typeIf you don’t want to explicitly qualify enumerator names and values to be ints (without explicit conversion int i = int(Color::red)), consider removing class from enum class
enum Color { red, green, blue };
int col = red; // OK: implicit conversion to int. col = 0
Union
If members p and i of Value are never used at the same time, consider the use of union. However, the language doesn’t keep track of which kind of value is held by union, so programmer must do that.
union Value {
Node* p;
int i;
}; // space optimization: union occupies only as much space as its largest member
struct Entry {
string name;
Type t;
Value v; // use v.p if t==Type::ptr, use v.i if t==Type::num (use enum Type for mannual bookkeeping)
};
Chapter 3: Modularity
Separate compilation where user code sees only declarations of the types and functions used. Can be done via:
- Header files:
#includea header file where its declarations are needed
- Modules (C++ 20): Define
modulefiles, compile them separately, andimportthem where needed.
Header files
Consider declaration that specify the interface in Vector.h. Then, the code in user.cpp (get and use Vector’s interface) and Vector.cpp (implementation, definition of Vector) shares the Vector interface, but are independent and separately compiled.
A .cpp file that is compiled by itself (including the h files it #include) is called a translation unit. Disadvantages of using header files:
- Compilation time: If
#include header.hin 100 translation units, the text ofheader.his processed by compiler 100 times.
- Order dependencies: If
#include header1.hbeforeheader2.hin declarations and macros,header1.hmight affect the code inheader2.h.
- Transitivity: All code needed to express a declaration in a header file must be present. Because header files may
#includeother header files.
Alternative: In the C and C++ programming languages, #pragma once is a non-standard but widely supported preprocessor directive designed to cause the current header file to be included only once in a single compilation.
Modules
A module is compiled once only, rather than in each translation unit. 2 modules can be imported in either order without changing their meaning. import is not transitive (users of your module do not implicitly gain access should your module #include or import something).
// in Vector.cpp
export module Vector; // defining a module called "Vector"
export class Vector {
// ...
};
export bool operator==(const Vector& v1, const Vector& v2)
{
// ...
}
// in user.cpp
import Vector;
#include <cmath> // you can mix #include with import
double sqrt_sum(Vector& v) { ... }
Return Type
auto mul(int i, double d) { return i*d; } // here "auto" means "deduce the return type from the return value"
auto next_elem() -> Elem** // different notation
Structured Binding
Structured binding does not imply a copy of the struct, returns types are constructed directly. Note that it is used for a class with no private data.
struct Entry {
string name;
int value;
};
Entry read_entry(istreams& is) { ... }
auto [name, val] = read_entry(is);
// common usage
map<string, int> mp;
for (const auto [key, value] : mp) { ... }
Chapter 4: Error Handling
Throw Exceptions
double& Vector::operator[](int i) {
if (!(0<i && i<size()) {
throw out_of_range{"Vector::operator[]"};
}
return elem[i];
}
void f(Vector& v) {
try {
// ...
} catch (const out_of_range& err) {
cerr << err.what() << '\n';
} catch (const std::length_error& err) {
// .. handle negative size
} catch (const std::bad_alloc& err) {
// ... handle memory exhaustion
}
}Throw transfers control to handler for exceptions of the type out_of_range is some function that called Vector::operator[](). It will unwind the function call stack to get back to the context of that caller.
Error Handling Alternatives
- Return value (error code): A failure is normal and expected, for example opening a file that does not exist, or error happens is one of a set of parallel tasks - we need to know which task failed.
- Throw Exception: when error cannot be handle by immediate caller, prelocate back up the call chain.
- Terminate: We cannot recover from the error, such as memory exhaustion. Restarting a thread, process or computer.
assert()
assert() a condition must hold at runtime, else program terminates. If not in debug mode, assert() is not checked.
assert(p != nullptr) // condition must hold at runtime
static_assert()
Perform simple checks on most properties that are known at compile time. Once use case of static_assert is to make assertions about the types used as parameters in generic programming.
constexpr double C = 29972.458;
constexpr double local_max = 160;
double speed = 5;
static_assert(speed<C, "can't go that fast"); // error: speed must be constant
static_assert(local_max<C, "can't go that fast"); // OK
noexcept
A function that should never throw exception can be declared noexcept. However, if exception is still thrown, std::terminate() is called immediately to terminate the program (deemed fatal error).
void user(int sz) noexcept {
Vector v(sz);
iota(&v[0],&v[sz],1); // fill v with 1,2,3,4...
// ...
};Chapter 5: Classes
By convention, we place public declarations of a class first, and the private declarations later.
Abstract Types
Concrete classes are placed on stack, and in other objects, initialize copy and move. In contrast, an abstract type (as long as one pure virtual function exist) is a type that completely insulate user from implementation details. Since we don’t know anything about representation of abstract type, not even its size, we must allocate on the free store and access them through references or pointers.
The word virtual means “may be redefined later in a class derived from this one”. (virtual function)
=0 syntax, pure virtual; that is some class derived from Container must define the function.
class Container {
public:
// no such thing as a virtual constructor
virtual double& operator[](int) = 0; // pure virtual function
virtual int size() const = 0; // const member function
virtual ~Container() {} // destructor
};
class Vector_container : public Container {
public:
Vector_container(int s) : v(s) {}
~Vector_container() {}
double& operator[](int i) override { return v[i]; } // override is optional, but good practice for compiler to catch mistakes, such as misspellings of function names or function signature
int size() const override { return v.size(); }
private:
Vector v;
};
Container c; // error: there can be no objects of an abstract class
Container* p = new Vector_container(10); // OK: Container is an interface for Vector_container
Virtual Functions
Implementation technique for compiler is to convert the name of virtual function to an index into a table of pointers to functions. The table is called virtual function table or vtbl.
Derived1 has ptr → vtbl (for Derived1) → points to matching functions.
Derived2 has ptr → vtbl (for Derived2) → points to matching functions.
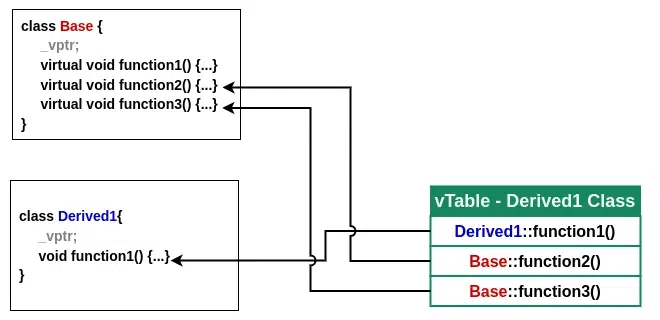
Space overhead is one pointer in each object with virtual functions plus vtbl for each class.
Benefits of Hierarchies
Interface Inheritance: Object of derived class can be used whenever an object of base class is required. Example: Container and Shape class, they are abstract classes.
Implementation Inheritance: Base class provides functions or data that simplifies implementation of derived classes. Smiley’s uses Circle’s constructor.
class Circle : public Shape {
public:
Circle(Point p, int rad) : x{p}, r{rad} {} // constructor
private:
Point x;
int r;
};
class Smiley : public Circle {
public:
Smiley(Point p, int rad) : Circle{p, rad}, mouth{nullptr} {}
~Smiley()
private:
vector<Shape*> eyes; // use vector<unique_ptr<Shape>> eyes to prevent resource leaks
Shape* mouth; // use unique_ptr<Shape> mouth to prevent resource leaks
};Classes in hierarchies - we tend to allocate them on free store using new, and we access them through pointer or references. Note: a virtual destructor is essential for an abstract class because object of derived class is usually manipulated/accessed through the abstract class. In particular it may be deleted through a pointer to base class. Thus, virtual function call ensures the proper destructor is called. In this case, Smiley’s destructor is called first, then it calls Circle’s destructor.
The size of derived class is its derived class members plus size of base class. See: https://stackoverflow.com/questions/8813756/inheritance-and-size-of-object
Chapter 6: Essential Operations
class X {
public:
X(Sometype); // ordinary constructor
X(); // default constructor
X(const X&); // copy constructor
X(X&&); // move constructor
X& operator=(const X&); // copy assignment
X& operator=(X&&); // move assignment
~X(); // destructor
};=default
If you are explicit about some defaults, other default definitions will not be generated.
If pointer points to something in the class that needs to delete, in which case default memberwise copy would be wrong.
Rule of Thumb: either define all of the essential operations or none.
class Y {
public:
Y(Sometype);
Y(const Y&) = default; // really want the default copy constructor
Y(Y&&) = default; // really want the default move constructor
};
=delete
use =delete to indicate that an operation is not to be generated.
Example: Base class, we don’t want to allow memberwise copy (due to ambiguity).
=delete can be used to “supress” any functions, not just essential member functions
class Shape {
public:
Shape(const Shape&) = delete; // no copying
Shape& oeprator=(const Shape&) = delete;
}
void copy(Shape& s1, const Shape& s2) {
s1 = s2; // compile-time error, Shape copy is deleted
};
Explicit/Implicit Conversions
A constructor taking single argument defines a conversion from its argument type. Implicit conversion is sometimes ideal, but not always. Define constructor to only allow “explicit” conversion:
class Vector {
explicit Vector(int s) { ... };
};
Vector v1(7); // v1 has 7 elements
Vector v2 = 7; // error! no implicit conversion from int to Vector.
// Without explicit keyword, v2 = 7; OK: v2 has 7 elements
Member Initializer
supply default values which are used whenever constructor doesn’t provide a value.
class complex {
double re = 0;
double im = 0;
public:
complex(double r, double i) : re{r}, im{i} {} // construct complex from 2 scalars {r,i}
complex(double r) : re{r} {} // construct complex from 1 scalar {r,0}
complex() {} // default complex {0,0}
}
Copying Containers
When a class is a resource handle (class responsible for object accessed through a pointer), default memberwise copy is typically a disaster.
void bad_copy(Vector v1) {
// using default copy
Vector v2 = v1;
v1[0] = 2; // v2[0] is now also 2
v2[1] = 3; // v1[1] is now also 3
}
// defining better copy semantics
class Vector {
public:
Vector(int s); // constructor
~Vector() { delete[] elem; } // destructor
// copy constructor
Vector(const Vector& a) : elem{new double[a.sz]}, sz{a.sz} {
for (int i = 0; i < sz; ++i) {
elem[i] = a.elem[i];
}
}
// copy assignment
Vector& operator=(const Vector& a) {
double *p = new double[a.sz];
for (int i = 0; i < a.sz; ++i) {
p[i] = a.elem[i];
}
// elements are copied before old elements are deleted,
// so if something wrong goes with the element copy and expection is thrown,
// old value of Vector is preserved
delete[] elem; // delete old elements
elem = p;
sz = a.sz;
return *this;
};
double& operator[](int i);
const double& operator[](int i) const;
int size() const;
private:
double* elem; // elem points to array of sz doubles;
int sz;
};
Moving Containers
Vector operator+(const Vector& a, const Vector& b) {
Vector res(a.size());
for (int i = 0; i < a.size(); ++i)
res[i] = a[i] + b[i];
return res;
}
void f(const Vector& x, const Vector& y, const Vector& z) { Vector r; r = x+y+z; };
// Note: res is never used again after the copy. Wasteful copy operations!
class Vector {
public:
// ...
Vector(const Vector& a); // copy constructor
Vector& operator=(const Vector& a); // copy assignment
// move constructor
Vector(Vector&& a) : elem{a.elem}, sz{a.sz} {
a.elem = nullptr;
a.sz = 0;
};
Vector& operator=(Vector&& a); // move assignment
};Given the definition, compiler will choose move constructor to implement the transfer of return value out of the function.
&& means r-value reference, and is a reference to which we bind an rvalue.
lvalue: something that can appear on LHS of an assignment. (i.e, the name of a variable, a function, a template parameter object(since C++20), or a data member, regardless of type, such as std::cin or std::endl)
rvalue: a value that you cannot assign to, such as an int returned by function call. Since nobody else can assign torvaluereference, we can safely “steal” it. res inoperator+()for Vectors is such example.- An
rvalueexpression is eitherprvalue(may not be polymorphic, such as a literal42, true or nullptror function call or or an overloaded operator expression whose return type is non-referenceit++, str1+str2)
- or
xvalue. (may be polymorphic, such as a function call or an overloaded operator expression, whose return type is rvalue reference to object, such asstd::move(x))
- An
Move constructor does not take const argument, since it is supposed to remove the value from the argument. Move assignment is defined similarly.
Copy elision
Note: Copy elision is compiler optimization that eliminates unnecessary copying of objects. copy-initialization is usually equivalent to direct-initialization in terms of performance, but not in semantics; copy-initialization still requires an accessible (i.e public) copy constructor.
GCC provides the -fno-elide-constructors option to disable copy-elision.
struct C {
explicit C(int a) { ... };
C(const C& a) { ... };
};
C c1(42); // direct-initialization, calls C::C(int)
C c2 = C(42); // copy-initialization, calls C::C(const C&), but copy is elided (aka omitted)
On the other hand, it is typically not possible to implicitly eliminate copy or move operations from assignments, so move assignments can be critical for performance.
Vector x(1000), y(2000), z(3000);
z = x; // we get copy assignment
y = std::move(x); // move assignment
// ... better not to use x here onwards
Resource Management & RAII (Resource Acquisition Is Initialization)
A resource that is not just memory is called a non-memory resource.
Vectors, string, map, unordered_maphold memory,
threadshold system threads
- fstreams (
ifstream, ofstream) hold file handles
- locks (
lock_guard, unique_lock)
- general objects (through
unique_ptrandshared_ptr)
Garbage collection is fundamentally a global memory management scheme. Clever implementations can compensate, but as systems are getting more distributed (caches, multicores and clusters) locality is more important than ever.
RAII: We let each resource have an owner in some scope and by default be released at the end of its owner’s scope.
Operator Overloading
Unfortunately, we cannot define the (.) operator dot to get smart references.
// operator can be defined as member function, conventionally done for =, ->, (), []
class Matrix {
// ...
Matrix& operator=(const Matrix& a); // assign a to *this; return reference to *this
}
// alternatively, most operators can be defined as free standing functions. It is convention to define binary operators with symmetric operands (such as A+B == B+A) as free standing functions in the namespace of its class.
namespace NX {
class Matrix {
};
Matrix operator+(const Matrix& m1, const Matrix& m2); // assign m1 to m2 and return sum
bool operator==(const Matrix& m1, const Matrix& m2);
};
Spaceship operator <=> By defining default <=>, all other relational operators are also implicitly defined. If non-default, other relational operators except == and != are defined.
class R {
auto operator<=>(const R& a) const = default;
};
void user(R r1, R r2) {
bool b1 = (r1 <=> r2) == 0; // r1 == r2
bool b2 = (r1 <=> r2) < 0 // r1 < r2
bool b3 = (r1 <=> r2) > 0 // r1 > r2
bool b4 = (r1 == r2); // OK: implicitly defined using default <=>
bool b5 = (r1 != r2); // OK
bool b6 = (r1 <= r2); // OK;
}
class R2 {
public:
int m;
auto operator<=>(const R2& a) const {
return a.m == m ? 0 : a.m < m ? 1 : -1;
}
}
void user(R2 r1, R2 r2) {
bool b4 = (r1 == r2); bool b5 = (r1 != r2); // error: no non-default ==
bool b6 = (r1 <= r2); // OK
}
User-defined Literals
Standard-Library Suffixes for Literals
| <chrono> | std::literals::chrono_literals | h, min, s, ms, us, ns | 123s is 123 seconds |
| <string> | std::literals::string_literals | s | “Surprise!”s is a std::string |
| <string_view> | std::literals::string_literals | sv | |
| <complex> | std::literals::complex_literals | i, il, if | 12.7i is imaginary so that 12.7i+47 is complex |
// example implementation of imaginary suffix to a complex number
constexpr complex<double> operator""i(long double arg) {
return {0, arg};
}
Chapter 7: Templates
Templates are compile-time mechanism, so it incurs no run-time overhead.
Templates are used in classes and/or functions, but never in code blocks
template<typename T>
class Vector {
private:
T* elem;
int sz;
public:
explicit Vector(int s);
~Vector() { delete[] elem; }
// ... copy and move operations
T& operator[](int i); // for non-const vectors
const T& operator[](int i) const; // for const vectors
int size() const ( return sz; )
};
template<typename T>
Vector<T>::Vector(int s) {
if (s < 0)
throw length_error{"Vector constructor: negative size"};
elem = new T[s];
sz = s;
}
template<typename T>
const T& Vector<T>::operator[](int i) const {
if (i < 0 || size() <= i)
throw out_of_range{"Vector::operator[]"};
return elem[i];
}
To support range-for loop for custom Vector, we need to define begin() and end() functions:
template<typename T>
T* begin(Vector<T>& x) {
return &x[0];
}
template<typename T>
T* end(Vector<T>& x) {
return &x[0] + x.size();
}
void write(Vector<string>& vs) {
for (auto &s : vs)
cout << s << '\n';
}
Value template arguments
Useful in many contexts, for example, Buffer allows us to create arbitrarily sized buffers with no use of heap.
Note: string literal cannot be template value argument.
- Error: template<string S>
- Workaround is
template<char* s>
template<typename T, int N>
struct Buffer {
constexpr int size() { return N; }
T elem[N];
}
Buffer<char, 1024> buf; // buffer of characters statically allocated (on the stack)
Template Argument Deduction
Vector<string> vs {"Hello", "World"}; // OK: Vector<string>
Vector vs1 {"Hello", "World"};
// OK: deduces to Vector<const char*> C-style string literal is const char*
Vector vs2 {"Hello"s, "World"s}; // OK: deduces to Vector<string>
Vector vs2 {"Hello"s, "World"}; // error: initalizer list is not homogenousTo resolve ambiguity, we can use concepts (C++ 20). Before that, when dealing with Vectors, we can use deduction guide to say “a pair of the same type should be considered iterators”.
template<typename T>
class Vector {
public:
Vector(initializer_list<T>); // initializer list constructor
template<typename Iter>
Vector(Iter b, Iter e) -> Vector<typename Iter::value_type>
// standard method is (iterator_traits)
// Vector(Iter b, Iter e) -> Vector<typename std::iterator_traits<Iter>::value_type>
struct iterator { using value_type = T; /* .. */ }; // specified value type = T
iterator begin();
};
Vector v1 {1,2,3,4,5} // element type is int
Vector v2(v1.begin(), v1.begin()+2); // pair of iterators, element type is int
Vector v3{v1.begin(), v1.begin()+2}; // element type is Vector::iterator{ } initializer syntax always prefers the initializer_list constructor (if present), so v3 is a vector of iterators, Vector<Vector<int>::iterator>
Function Templates
// function can have templates too
template<typename S, typename V>
V sum(const Sequence& s, Value v) {
for (auto x : s)
v += x;
return v;
};Function template can be a member function, but not virtual members, since compiler would not know all instantiations of such a template in the program, so it could not generate a vtbl.
Function Objects (aka Functors)
Function objects used to specify meaning of key operations of a general algorithm (such as Less_than for count()) are sometimes referred to as policy objects.
template<typename T>
class Less_than {
const T val;
public:
Less_than(const T& v) : val{v} {}
bool operator()(const T& x) const { return x<val; } // call operator
}
template<typename C, typename P>
int count(const C&c, P pred) {
int cnt = 0;
for (auto &x : c)
if (pred(x))
++cnt;
return cnt;
}
const Vector<int>& vec{1,2,3,4,5};
int x = 5;
cout << "number of values less than " << x << ": " << count(vec, Less_than{x});
Lambda Expressions
- capture list, Capture nothing is [], all local names by reference is [&], all local names by value is [=], Capture only x by reference is [&x], only copy of (by value) x is [x]. For lambda defined within member function, [this] captures object by reference, [*this] captures copy of (by value) object .
void fn(const list<string>& lst, const string& s) {
cout << "number of values less than " << s << ": " <<
count(lst, [&](const string& a) { return a<s });
};
// perform updates by pass by reference
vector<unique_ptr<Shape>> v;
for_each(v, [](unique_ptr<Shape>& ps){ ps->rotateBy(45); }); // note arg is non const
We can use lambda with auto parameter, known as a generic lambda. We can further constrain the parameter using concepts (i.e define Pointer_to_class to require * and → and write)
// consider simplified for-each
for_each(v, [](auto& ps){ ps->rotateBy(45); });
for_each(v, [](Pointer_to_class auto& ps){ ps->rotateBy(45); ps->draw(); });
Finally()
Use finally() to provide RAII for types without destructors that require “cleanup operations”.
void old_style(int n) {
void* p = malloc(n*sizeof(int));
auto act = finally([&]{ free(p); }); // call lambda upon scope exit
// p is implicity freed upon scope exit
}[[nodiscard]] : Attributes (introduced in C++17) to member functions to highlight at compile time which return values should not be ignored.// sample implimentation of finally
template<class F>
[[nodiscard]] auto finally(F f) {
return Final_action{f};
}
template<class F>
struct Final_action {
explicit Final_action(F f) : act{f} {}
~Final_action() { act(); }
F act;
};
Template Mechanisms (Variable Templates, Aliases, Compile-Time if)
- Variable Templates: often used as constants. STL uses variable templates to implement math constants like
piandlog2e.
template<class T>
constexpr T viscosity = 0.4; // viscosity is of type T
auto vis2 = 2*viscosity<double>;
template<class T>
constexpr vector<T> external_acc = {T{}, T{-9.8}, T{}}; // external_acc is a vec of T
auto acc = external_acc<float>; - Aliases
using size_t = unsigned int;
template<typename C>
using Value_type = C::value_type;
template<Container C>
void algo(Conatiner& c) {
Vector<Value_type<Container>> vec; // if Container is list<int>, then the value_type is int, so vec is Vector<int>
}
template<typename Value>
using String_map = map<string, Value>;
String_map<int> m;- Compile-time if: The compiler checks only the selected branch of an
if constexpr, offering optimal performance and locality of optimization.
template<typename T>
void update(T& target) {
if constexpr(is_trivially_copyable<T>)
simple_and_fast(target); // never put try-catch in the if block
else
slow_and_safe(target);
}
Chapter 8: Concepts and Generic Programming
A concept is a compile-time predicate specifying how one or more types can be used. Note that when defining a concept, a non-template variable cannot be ‘concept’
template<typename T, typename T2 = T> // required
concept Equality_comparable =
requires (T a, T2 b) {
{ a == b } -> std::convertible_to<bool>; // must be able to compare T to T2 with ==
{ a != b } -> std::convertible_to<bool>; // compare T to T2 with !=
{ b == a } -> std::convertible_to<bool>; // must be able to compare T2 to T with ==
{ b != a } -> std::convertible_to<bool>; // compare T2 to T with !=
}
static_assert(Equality_comparable<int, double>); // OK
static_assert(Equality_comparable<int>); // OK
static_assert(Equality_comparable<int, string>); // compile-error, assertion fails
struct S { int a };
static_assert(Equality_comparable<S>); // compile-error, assertion failsThe typename T2 = T says that if we don’t specify the second template argument, then default is T.
Most template arguments require specific requirements for code to compile properly and generated code to work properly. We can use concepts to constrain templates.
template<Sequence Seq, Number Num>
requires Arithmetic<range_value_t<Seq>,Num> // requirements clause
Num sum(Seq s, Num n);
//verbose way of writing
template<typename Seq, typename Num>
requires Sequence<Seq> && Number<Num> && Arithmetic<range_value_t<Seq>, Num>Requires-expression is a predicate that evaluates to true if the statements in the code are valid and false if not, usually not seen in ordinary code. They belong in the implementation of abstractions. If you see requires requires in your code, it is probably too low level.
// example of requires expression.
requires(Iter p, int i) { p[i]; p+i; }
template<forward_iterator Iter>
requires x
void advance(Iter p, int n) { p+=n; }
Consider the implementation of Sequence:
template <typename S>
concept Sequence = input_range<S>; // using STL concept input_range
// implementation
template <typename S>
concept Sequence = requires(S a) {
typename range_value_t<S>; // S must have valid value type 't' stands for type
typename iterator_t<S>; // S must have valid iterator type 't' stands for type
{ a.begin() } -> same_as<iterator_t<S>>; // begin() that returns iterator
{ a.end() } -> same_as<iterator_t<S>>;
requires input_iterator<iterator_t<S>>; // S's iterator must be input iterator
requires same_as<range_value_t<S>, iter_value<S>>;
};
Check of template definition only occurs at the time of instantiation (late into the compilation process). This allows for incomplete concepts during development, and debugging a template without affecting its interface.
template<equality_comparable T>
bool cmp(T a, T b) { return a < b; }
bool b0 = cmp(cout,cerr); // error: ostream doesnt support ==
Auto
Remember that auto can be used to indicate that the object should have the type of its initializer.
- Concepts can be used for constraining function arguments.
auto twice(Arithmetic auto x) { return x+x; }; // just for numbers
string s = "Hello";
auto x2 = twice(s); // error: a string is not Arithmetic
// Note that auto keyword is still needed
auto twice(Arithmetic auto x); // OK
auto twice(Arithmetic x); // error: 'auto' required after concept nameThis code is valid using C++20: This is a special case of unconstrained auto parameter.
int function(auto data) { ... } // do something, there is no constraint on data- Concepts can constrain the initialization of variables.
Arithmetic auto ch2 = open_channel("foo"); // error: return value is not Arithmetic- Concepts can constrain the return type, which improves readability and debugging.
Number auto fn(int x) {
//...
return fct(x); // an error, unless fct(x) returns Number
}
// alternatively
auto fn(int x) { ... };
Number auto y = fn(x);
Variadic Templates
Defined to accept an arbitrary number of arguments of arbitrary types. Traditional implementation has been to separate the first argument from the rest then recursively call the template for tail arguments.
Parameter declared with … is called a parameter pack.
Here tail is a function argument parameter pack, where elements are of the types found in the template argument parameter pack Tail.
template<typename T>
concept Printable = requires(T t) { std::cout << t; }
template<Printable T, Printable... Tail>
void print(T head, Tail... tail) {
cout<<head<<'';
if constexpr(sizeof...(tail)> 0) // to prevent the zero argument case
print(tail...);
}
Fold expressions
For simple variadic templates, can iterate over elements of the parameter pack.
// rightfold implementation (v[0] + (v[1] + ( v[2] + ... (v[n-1] + 0))))
template<Number... T>
int sum(T... v) {
return (v + ... + 0); // add all elements of v starting from 0
}
// leftfold implementation ((((0 + v[0]) + v[1]) + v[2]) + ... ) + v[n-1])
template<Number... T>
int sum(T... v) {
return (0 + ... + v); // all all elements of v to 0
}
// leftfold implementation
template<Printable... T>
void print(T&& args) {
(std::cout<< ... << args) <<'\n'
}
Template Compilation Model
To use an unconstrained template, its definition (not just its declaration) must be in scope at its point of use. When using header files and #include, this means template definitions are found in header files, not in .cpp files. For example, standard header <vector> holds the definition of vector.
Chapter 9: STL Overview
The range namespace
STL offers algorithms like sort() and copy(), int two versions:
using namespace std;
using namespace ranges;
void f(vector<int>& v) {
sort(v.begin(), v.end()); // error: ambiguous
sort(v); // error: ambiguous
}
// to protect against ambiguities, introduce range version of STL into a scope
using namespace std;
void g(vector<int>& v) {
sort(v.begin(), v.end()); // OK
ranges::sort(v); // OK
using ranges::sort;
sort(v); // OK
}
Chapter 10: Strings and Regular Expressions
By default definition, string literal is const char*. To get a literal of type std::string, use a “s” suffix. You need to use the namespace std::literals::string_literals.
string name = "Niels Stroustrup";
string s = name.substr(6,10); // s = "Stroustrup" start at idx 6, length 10
name.replace(0,5,"nicholas"); // name = "nicholas Stroustrup" start at idx 0, length 5
name[0] = toupper(name[0]); // name = "Nicholas Stroustrup"
// if you need C-style string
printf("For people who like printf %s\n", s.c_str()); // s.c_str() returns pointer to s's characters
String Implementation
These days, string is usually implemented using the short-string optimization. Short string values (usually about 14 chars) are kept in the string object itself, only longer strings are placed on the free store. Especially in multi-threaded implementations memory allocation can be costly.
When string value changes from short to long/long to short, it adjusts appropriately.
Another implementation/optimization is copy on write, but could be problematic in multithreaded programs. See: https://stackoverflow.com/questions/1466073/how-is-stdstring-implemented
String View
string_view gives access to a contiguous sequence of characters (can be string, C-style string, etc). Think of string_view as a pointer to “read-only” view of its characters, and for string_view to be used, it must point to something.
using namespace std::literals::string_view_literals; // to use the sv suffix
string cat(string_view sv1, string_view sv2) {
string res{sv1};
return res += sv2;
}
string king = "Harold";
auto s1 = cat("Edward", "Stephen"sv); // OK, const char* and string_view
auto s2 = cat({&king[0],2}, {&king[2],4}); // OKBy using sv suffix, the length is computed at compile time, as compared to const char * that requires counting of characters.
Chapter 11: Input and Output
ostream converts typed objects to stream of chars (bytes)
istream converts a stream of chars (bytes) to typed objects
I/O stream classes have destructors that free all resources owned (i.e buffers and file handles). They are example of RAII.
By default, a whitespace character, such as a space or newline, terminates the read, so:
cout<<"Please enter your name\n";
string str; // if input is Eric Bloodaxe, only Eric will be cin
cin>>str;
cout<<"Hello, "<<str<<"!\n"; // Hello, Eric!
// You can read a whole line using the getline function
cout<<"Please enter your name\n";
string str;
getline(cin,str);
cout<<"Hello, "<<str<<"!\n";
iostream
is>>i returns a reference to is, and iostream yields true if the stream is ready for another operation. In this case, is will read until something that is not an int is encountered.
vector<int> read_ints(istream& is) {
vector<int> res;
for (int i; is>>i; )
res.push_back(i);
return res;
}
vector<int> read_ints(istream& is, const string& terminator) {
vector<int> res;
for (int i; is>>i; )
res.push_back(i);
if (is.eof()) // fine: end of file
return res;
if (is.fail()) // failed to read an int, was is the string terminator?
is.clear(); // reset state to good()
string s;
if (is>>s && s==terminator)
return res;
is.setstate(ios_base::failbit); // add fail() to is's state
}
auto v = read_ints(cin, "stop");
I/O Streams of User Defined Types
User-defined output operator takes its output stream by reference as first argument, and returns it as result.
struct Entry {
string name;
int number;
};
ostream& operator<<(ostream& os, const Entry& e) {
return os << "{\"" << e.name << "\", " << e.number << "}";
}User-defined input operator is more complicated because it has to check for correct formatting and deal with errors.
// for example, read {"sample name", 12345}
istream& operator>>(istream& is, const Entry& e) {
char c, c2;
if (is>>c && c=='{' && is>>c2 && c2=='"') {
string name;
while(is.get(c) && c!='"') // we use is.get(c) instead of is>>c as the latter skips over whitespaces (tabs, spaces, newlines), but former does not
name+=c;
if(is>>c && c==',') { // here we use cin>>c to ignore whitespaces
int number = 0;
if (is>>number>>c && c=='}')
e = {name,number};
return is;
}
}
is.setstate(ios_base::failbit); // register the failure in the stream;
return is;
}
// example
{ "John Marwoord Cleese", 123456 }
for (Entry ee; cin>>ee; )
cout << ee << '\n'; // write ee to cout, {"John Marwoord Cleese", 123456} formatted
Stream Formatting
The simplest forms of formatting controls are called manipulators and are found in <ios>, <istream>, <ostream>, <iomanip>.
cout<<1234<<' '<<hex<<1234<<' '<<oct<<1234<<' '<<dec<<1234<<'\n'; // 1234 4d2 2322 1234We can explicitly set the output format for floating point numbers.
constexpr double d = 123.456;
cout<<d<<";"
<<scientific<<d<<"; " // 1.234560e+02; (normalized - 1 digit before exponent)
<<hexfloat<<d<<"; "
<<fixed<<d<<"; " // 123.456000; precision specifies the max number of digits
<<defaultfloat<<d<<";\n"; // 123.456; lets the implementation choose the format
// 123.456; 1.234560e+02; 0x1.edd2f1a9fbe77p+6; 123.456000; 123.456;With precision(), floating-point values are rounded, not truncated. precision() doesn’t affect int.
cout.precision(8);
cout<<1234.56789<<' '<<123.456<<' '<<123456<<'\n';
// 1234.5679 123.456 123456
Format()
STL provides type-safe, printf() style formatting.
#include <format>
int val = 127;
string s = format("Hello, {}\n", val);
cout<<s; // Hello, 127
cout<< format("{} {:x} {:o} {:d} {:b}\n", 1234,1234,1234,1234,1234);
// The number before the : allows us to switch up order/format argument more than once
cout<< format("{0:} {0:x} {0:o} {0:d} {0:b}\n", 1234);
// 1234 4d2 2322 1234 10011010010
// for floating point formats, e for scientific, a for hexfloat, f for fixed, g for default
cout<< format("{0:} {0:e} {0:a} {0:f} {0:g}\n", 123.456);
// precision specifier
cout << format("{:.8} {:.4} {}\n", 1234.56789, 1234.56789, 123456);
Vformat()
takes a variable as a format, but this increases flexibility and the chance for run-time errors.
string fmt = "{} {}";
cout<<vformat(fmt, make_format_args("arg1","arg2")); // OK: arg1 arg2
fmt = "{:%F}";
cout<<vformat(fmt, make_format_args(2)); // run-time error: format and arg mismatch
//if format was used, compile time error instead
string buf;
format_to(back_inserter(buf), "iterator: {} {}\n", "Hi!", 2022);
cout<<buf; // iterator: Hi! 2022
Streams
Streams cannot be copied; always pass them by reference.
All STL streams are templates with character type as parameter. ostream is basic_stream<char>, wostream is basic_stream<wchar_t>. Wide character streams (wostreams) can be used for unicode.
WCHAR(orwchar_ton Visual C++ compiler) is used for Unicode UTF-16 strings.CHAR(orchar) can be used for several other string formats: ANSI, MBCS, UTF-8.
Standard streams
cin // standard input
cout // standard output
cerr // unbuffered error output
clog // buffered logging outputFile streams in <fstream>
A path in C++ is not checked for validity until it is used. Validity depends on the conventions of the system on which the program runs.
ifstream // for reading from a file
ofstream // for writing to a file
fstream // for reading and writing to a file
void use(path p) {
ofstream f{p};
if (!f) error("bad file name: ", p);
f<<"Hello file!";
};String Streams in <sstream>
istringstream // for reading from a string
ostringstream // for writing to a string
stringstream // for reading and writing to a string
stringstream can be used for both reading and writing. Consider an example function that can convert any type with string representation into another representation that also can be represented as a string.
template<typename Target=string, typename Souce=string>
Target to(Source arg) {
stringstream buf;
Target result;
if (!(buf<<arg) || !(buf>>result) || !(buf>>std::ws).eof() )
throw runtime_error{"to<>() failed"}; // write arg to stream, read result from stream, check stream empty (anything left in stream)
return result;
};
auto x1 = to<string,double>(1.2); // very explicit and verbose
auto x2 = to<string>(1.2); // source is deduced to double
auto x3 = to(1.2); // <> is redundant, source deduced to double, target defaulted to string
Memory Streams
spanstream, ispanstream and ospanstream (will not become official before C++ 23). Spanstreams are similar to stringstreams, except they take spans (i.e std::vector and std::array) rather than string as an argument.
Note: Attempts to overflow the target buffer sets the stream state to failure.
void user(int arg) {
array<char,128> buf;
ospanstream ss(buf);
ss<<"write "<<arg<<" to memory\n";
}
Synchronized Streams
In multithreaded system, either one thread uses stream, else ensure access to streams are synchronized - only one thread at a time gains access.
// different threads may introduce data race
void unsafe(int x, string& s) { cout<<x; cout<<s; }
void safer(int x, string& s) { osyncstream oss(cout); oss<<x; oss<<s; }
C-style I/O
If you don’t use C-style I/O and care about I/O performance, call
ios_base::sync_with_stdio(false); // avoid overhead, where cin/cout can be slowed down to be compatiable with C-style I/OChapter 12: Containers
Vectors
Typical implementation of vector will consist of a handle holding pointers to first element, one-past-the-last-element, and one-past-the-last allocated space. It also holds an allocator (alloc) to acquire and release memory. Default allocator uses new and delete to acquire and release memory.
template<typename T>
class Vector {
allocator<T> alloc;
T* elem; // pointer to first element
T* space; // pointer to first unused and uninitialized slot
T* last; // pointer to last slot
public:
int size() const { return space-elem; }
int capacity() const { return last-elem; }
void reserve(int newsz); // increase capacity() to newsz
void push_back(const T& t); // copy t into Vector
void push_back(const T&& t); // move t into Vector
}Note: If you have a class hierarchy that relies on virtual functions to get polymorphic behaviour, do not store objects directly in a container. Instead store a pointer/smart pointer.
vector<Shapre> vs; // you cannot store a Circle or Smiley!
vector<Shape*> vps; // better
vector<unique_ptr<Shape>> vups; // OK
List/Forward List
list: doubly-linked list. foward_list: singly linked list
- A list is a sequence, and we can use the for-range loop.
- To insert/delete element in the list, we can use an iterator.
In general if you have insertions into the data-structure (other than at the end) thenvectormay be slower, otherwise in most casesvectoris expected to perform better thanlistif only for data locality issues, this means that if two elements that are adjacent in the data-set are adjacent in memory then the next element will already be in the processor's cache and will not have to page fault the memory into the cache.
Also keep in mind that the space overhead for avectoris constant (3 pointers) while the space overhead for alistis paid for each element, this also reduces the number of full elements (data plus overhead) that can reside in the cache at any one time.
// Note: DLL supports ++p and --p but LL only supports ++p (why? obvious)
// DLL uses erase/insert (before) while LL uses erase_after/insert_after
void fn()
{
list<int> lst{1,2,3,4,5};
lst.insert(lst.begin(), 0); // insert elem BEFORE the pointed elem
lst.erase(--lst.end()); // remove pointed elem
for (auto p = lst.begin(); p != lst.end(); p++) { cout<<*p<<" "; }
}
// 0 1 2 3 4
void fn2()
{
forward_list<int> lst{0,-1,2,3,4};
lst.insert_after(lst.begin(), 1); // insert elem AFTER the pointed elem
lst.erase_after(++lst.begin()); // remove single elem AFTER pointed elem
for (auto p = lst.begin(); p != lst.end(); p++) { cout<<*p<<" "; }
}
// 0 1 2 3 4
Unordered_map
There is default hash function for strings as well as other built in STL types. A hash function is often implemented as a functor.
struct Record {
string name;
int product_code;
};
struct Rhash { // a hash function for Record
size_t operator()(const Record& r) const {
// assuming name or product_code itself is not UID, we can use ^
return hash<string>()(r.name) ^ hash<int>()(r.product_code);
}
};
unordered_set<Record,Rhash> my_set;
Allocators
Assume a long running system used an event queue using vectors as events. Due to fragmentation, after 100K events had been passed among 16 producers and 4 consumers, more than 6GB memory consumed.
// assuming events are stored as ptrs in q
list<shared_ptr<Event>> q;Solution? Use a pool allocator instead. Pool allocator is an allocator that manages objects of a single fixed size and allocates space for many objects at a time, rather than individual allocations. Now, after 100K events has been passed to 16 producers and 4 consumers, less than 3 MB used.
std::pmr::synchronized_pool_resource pool; // make pool
struct Event {
vector<int> data = vector<int>{512,& pool}; // let Events use pool
}
list<shared_ptr<Event>> q{&pool}; // let q use pool
// sample producer code
void producer() {
for (int i=0; n!=LOTS; ++n) {
scoped_lock lk{m}; // m is mutex
q.push_back(allocate_shared<Event,pmr::polymorphic_allocator<Event>>{&pool});
cv.notify_one();
}
}
Container Overview
k=c.capacity() // k is number of elements that c can hold without new allocation
c.reserve(k); // INCREASE capacity to k, if k<=c.capcity(), c.reserve(k) does nothing
c.resize(k); // make number of elements k, added elements have default value value_type{}
v.push_back(pair{1, "copy or move"}); // make a pair and then copy an object into container.
v.emplace_back(1, "build in place"); // NOTE: pass the args only, takes args for an element's constructor and builds the object in a newly allocated space in the container.
Chapter 13: Algorithms
vector<int> vec;
list<int> lst;
copy(vec.begin(), vec.end(), back_inserter(lst)); // append to back of lstThe call for back_inserter(lst) constructs an iterator for lst that adds elements to the end of the container, and using STL eliminates explicit call to realloc.
Iterators
bool has_c(const string& s, char c) {
auto p = find(s.begin(), s.end(), c); // use find
return p!=s.end();
}
template<typename C, typename V>
vector<typename C::iterator> find_all(C& c, V v) {
vector<typename C::iterator> res; // to refer to a type member of a template parameter, use ‘typename C::iterator’
for (auto p = c.begin(); p!=c.end(); ++p) {
if (*p==v)
res.push_back(p);
}
return res;
}
void test()
{
string m{"Mary had a little lamb"};
for (auto p : find_all(m, 'a')) {
if (*p != 'a')
cerr<<"a bug!\n";
}
}typename in typename C::iterator needed to inform compiler that C’s iterator is supposed to be a type and not a value of some type.
Iterators are used to separate algorithms and containers. An algorithms operates on its data through iterators and knows nothing about the container. A container knows nothing about the iterator algorithms operating on its elements - it supply iterators upon request.
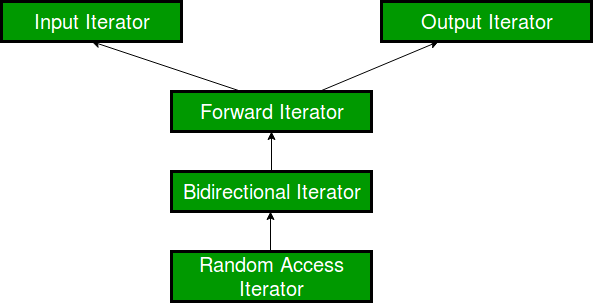
- For various STL algorithms like std::nth_element, std::sort, you must have found their template definition consisting of objects of type Random-access Iterator.
- For various STL algorithms like std::reverse, std::next_permutation and std::reverse_copy you must have found their template definition consisting of objects of type Bidirectional Iterator.
- For various STL algorithms like std::search, std::search_n, std::lower_bound, you must have found their template definition consisting of objects of type Forward Iterator.
- For various STL algorithms like std::copy, std::move, std::transform, you must have found their template definition consisting of objects of type Output Iterator. Output Iterators can be assigned values in a sequence, but cannot be used to access values (opposite of Input Iterators)
- For various STL algorithms like std::find, std::equal, std::count, you must have found their template definition consisting of objects of type Input Iterator. They be used in sequential input operations, where each value pointed by the iterator is read-only once and then the iterator is incremented.
What are iterators really? For example, in vectors, iterator can be pointers, or pointers with position index. Meanwhile, a list iterator must be more complicated because a list does not know where the next element of the list is. Thus, a list iterator might be a pointer to a link (link node).
Containers knows its iterator types (types are determined based on the template arguments provided when the container is instantiated, and compiler resolves it during compilation process) and makes them available under the conventional names of iterator and const_iterator.
Stream Iterators
Containers are not the only place where we find sequence of elements. The notion of iterators can be usefully applied to input/output.
void fn1() {
ostream_iterator<string> oo{cout}; // write strings to cout
vector<string> vec{"Hello, ", "world!\n"};
copy(vec.begin(), vec.end(), oo);
}
void fn2() {
ostream_iterator<string> oo{cout};
*oo = "Hello, ";
++oo;
*oo = "world!\n";
}
Predicates
The find algorithm provides a way of looking for a specific value. A more general variant looks for a predicate. We can pass a functor (function object) to be compared using find_if.
map<string, int> m;
auto p = find_if(m, [](const auto& r) { return r.second > 42; });
struct Greater_than {
int val;
Greater_than(int v) : val{v} {}
bool operator()(const pair<string,int>& r) { return r.second>val; }
};
auto p = find_if(m, Greater_than{42});
Parallel Algorithms
Parallel Execution: tasks are done on multiple threads (often running on several processor cores)
Vectorized Execution: tasks are done on single thread using vectorization, aka SIMD (Single Instruction, Multiple Data)
// Only from C++ 17 onwards, works on find/find_if, sort, count/count_if
#include <execution>
sort(execution::seq, v.begin(), v.end()); // sequential, same as default
sort(execution::par, v.begin(), v.end()); // parallel
sort(execution::unseq, v.begin(), v.end()); // vectorized
sort(execution::par_unseq, v.begin(), v.end()); // parallel and/or vectorizedHowever, these execution policies indicators are just hints. Compiler and/or run-time scheduler will decide how much concurrency to use. Many parallel algorithms are primarily for numeric data. Note: in parallel execution - you must be sure to avoid data races and deadlocks.
Chapter 14: Ranges
C++ 20. The range library includes set of standard algorithms that support activities like data filtering, transformation, and sorting on constrained types (using concepts) are in the <ranges> in namespace ranges.
There are different ranges (concepts) corresponding to the different kinds of iterators, like input_range, forward_range, bidirectional_range (consider: list vs forward_list), random_access_range (consider: vector/deque vs map/set), contiguous_range
The ranges library includes range algorithms, which are applied to ranges eagerly, and range adaptors, which are applied to views lazily.
Views
Views is a way of looking at a range. Views are also known as range adaptors.
#include <ranges>
void user(forward_range auto& r) {
for (int x : ranges::take_view{ranges::filter_view{r, [](int x) { return x%2;} }, 3})
cout << x << ' ';
}
// STL Views. v is a view, r is range, p is predicate, n in integer
v=filter_view{r,p}
v=transform_view{r,f}
v=take_view{r,n} // v is at most n elements from r
v=drop_view{r,n} // v is elements from r starting with the n+1th elementNote: Actually, a view offers an ‘interface’ that is very similar to that of a range, so in most cases we can use a view whenever we can use a range in the same way. The key difference is - view doesn’t own its elements, it is not responsible for deleting the elements of its underlying range - that’s the ranges responsibility.
auto bad() {
vector v = {1,2,3,4};
return filter_view{v,odd}; // error: v will be destroyed before the view
}
Generators
Generators are factories, useful for generating ranges on a fly. Some range factories below:
| v=empty_view<T>{} | v is empty range of type T elements |
| v=single_view{x} | v is the range of one element x |
| v=iota_view{x} | v is infinite range of elements, x, x+1, x+2, x+3, … (incrementing using ++) |
| v=iota_view{x,y} | v is finite of elements from x … to y-1. (incrementing using ++) |
| v=istream_view<T>{is} | v is range obtained by calling >> for T on is |
for (int x : ranges::iota_view(2,5)) {
cout<< x << ' ';
}
auto cplx = ranges::istream_view<complex<double>>(cin);
for (auto x : ranges::transform_view(cplx, [](auto z){ return z*z; })) {
cout << x << ' ';
}
Pipelines
Initial r has to be a range or a generator.
auto user(ranges::forward_range auto& r) {
auto odd = [](int x){ return x%2; };
for (int x : r | views::filter(odd) | views::take(3)) {
cout << x << ' ';
}
return r | views::filter(odd) | views::take(3);
}
vector<int> r = {1,2,3,4};
ranges::take_view tv = user(r);
for (int x : tv) {
cout<< x << ' ';
}
Concepts Overview
1.1 Types Concepts: Concepts defining properties of types and the relations among types
same_as<T,U> // T is same as U
derived_from<T,U> // T is derived from U
convertible_to<T,U> // T can be converted to U
// to specify a common pair of types
using common_type_t<Bigint, long> = Bigint; // suitable definition for Bigint1.2 Comparison Concepts
equality_comparable_with<T,U> // T and U can be compared using ==
equality_comparable<T> // T and T can be compared using ==
totally_ordered_with<T,U> // T and U yield total order, < <= == >= >
totally_ordered<T> // strict total ordering T and T1.3 Object concepts
destructible<T>, constructible_from<T,Args>, default_initializable<T>
move_constructible<T> // A T can be move constructed
copy_constructible<T> // A T can be copy constructed and move constructed
movable<T> // move constructable<T>, assignable<T&, T>, and swapable<T>
copyable<T> // copy constructable, movable<T> and assignable<T, const T&>
semiregular<T> // copyable<T> and default constructable<T>
regular<T> // semiregular<T> and equality_comprable<T>1.4 Callable concepts
invocable<F,Args> // An F can be invoked with argument list of type Args
regular_invocable<F,Args> // invocable<F,Args> and is equality preservingEquality preserving that means x==y implies f(x) == f(y).
Callable concepts also include relation, equivalence relation (reflexive aRa, symmetric aRb → bRa, and transitive aRb and bRc → aRc), and strict weak order (i.e <, not compare apples and oranges)
2.1 Iterator concepts - Since STL algorithms access containers/data through iterators, we need concepts to classify properties of iterator types.
input_iterator<I>, output_terator<I>, forward_iterator<I>, bidirectional_iterator<I>, random_access_iterator<T>, contiguous_iterator<I> // (random access for elements in contiguous memory)
permutable<I> // forward iterator supporting move and swap
mergable<I1,I2,R,O> // merge sorted sequences of I1 and I2 into O using relation<R>
sortable<I> // sort I sequences using less
sortable<I,R> // sort I sequences using relation<R> 2.2 Range concepts - define properties of ranges
// input_range<R>, output_range<R>, forward_range<R>, bidrectional_range<R>, random_access_range<R>, contiguous_range<R>
range<R> // range with begin iterator and sentinel
sized_range<R> // range that knows its size in constant time
view<R> // range with constant time copy, move, assignment
// common_range<R>
#include <ranges>
struct A
{
char* begin();
char* end();
};
static_assert( std::ranges::common_range<A> );
struct B
{
char* begin();
bool end();
}; // not a common_range: begin/end have different types
static_assert( not std::ranges::common_range<B> );
struct C
{
char* begin();
}; // not a common_range, not even a range: has no end()
static_assert( not std::ranges::common_range<C> );
int main() {}
Chapter 15: Pointers and Containers
Pointers
Owning pointers is one that is responsible for eventually deleting the object it refers to.
Non-owning pointer (T* or a span or a string_view) can dangle, that is, point to a location where an object has been deleted or gone out of scope.
Reading or writing through a dangling pointer, the result of doing so is technically undefined (aka the best we hope for is a crash, because that is preferable to a wrong result). Read means getting arbitrary value, write scrambles unrelated data structure.
- Don’t retain a pointer to local object after object goes out of scope.
- Use owning pointers to objects allocated on the free store
- Pointers to static objects (i.e global variables) can’t dangle
- Leave pointer arithmetic to implementation or resource handles (such as
vectorsandunordered_map)
The use of a constructor/destructor pair in Vector to manage lifetime of its elements is an example and all STL containers are implemented in similar ways. For example, in lock classes:
mutex m; // used to protect access to shared data
void f() {
scoped_lock lck{m}; // acquire the mutex m
// ... manipulate the shared data ...
}A thread will not proceed until lck’s constructor has acquired the mutex. The corresponding destructor releases the mutex - scoped_lock’s destructor releases the mutex when the thread of control leaves f() (through return, by falling off the end of the function, or through an exception throw). This is an application of RAII.
unique_ptr and shared_ptr
What about objects allocated on the free store? We have smart pointers to help manage:
unique_ptr: represents unique ownership (its destructor destroys its object)
shared_ptr: represents shared ownership (the last shared pointer’s destructor destroys the object).
Thestd::shared_ptruses automatic reference counting to track the number ofstd::shared_ptrinstances pointing to the object. The reference count increments and decrements are thread-safe because the it is implemented using atomic operations. However, accessing the object itself is not thread-safe if the object itself is not thread-safe. It’s the user’s responsibility to ensure the object access is thread-safe and mutual exclusion locks are often used.
When do we need pointer semantics?
- When we share an object, we need pointers (or references) to refer to shared object, so can use
shared_ptr
- When we refer to polymorphic object in OOP code, we need pointer (or reference) because we don’t know the exact type (or even size) of object, so can use
unique_ptr
- A shared polymorphic object typically requires
shared_ptr
When do we not need to use pointers? When returning a collection of objects from a function, container is a resource handle that will use copy elision and move semantics.
Polymorphism and Object Slicing
object slicing: when a derived class object is assigned to a base class object, the derived class object’s extra attributes are sliced off (not considered) to generate the base class object, so polymorphism doesn’t work.
Base c = Derived(); // c object is a Base, not Derived
Now take
Base* c = new Derived();We can avoid the unexpected behavior use the use of pointers or references. c just points to some place in memory (since pointers/references of any type takes the same amount of memory), and you don't really care whether that's actually a Base or a Derived, but the call to a virtual method will be resolved dynamically.
std::array
Array vs vector. std::array has performance advantage by directly accessing elements allocated on stack rather than allocating elements on free store and accessing them indirectly through the vector (a handle).
But stack is a limited resource (especially on some embedded systems), and may cause stack overflow. OS imposes strict size limit else if the stack would be allowed to grow arbitrarily large, errors like infinite recursion would be caught very late, when OS resources are exhausted.
Generally, stack’s LIFO structure keeps track of call stack and local variables. Because of LIFO structure, moving objects around becomes inefficient. Also if you create many threads, they will need one stack each. If all stacks are allocating multi-MBs, but not using it, space will be wasted.
std::array vs built in array. std::array knows it size, and it can be copied with =.
array<int> a1 = {1,2,3};
auto a2 = a1; // copy
a2[1] = 5;
a1 = a2; // assignAnother benefit - saves user from surprising conversions. Example: class hierarchy.
Circle a1[10];
array<Circle,10> a2;
Shape* p1 = a1; // OK: disaster waiting to happen
Shape* p2 = a2; // error: no conversion of array<Circle,10> to Shape*
p1[3].draw(); // disaster - if sizeof(Shape) < sizeof(Circle), subscripting a Circle[] through Shape* gives wrong offset.
std::bitset
For bits that don’t fit into a long long int (often 64 bits), using a bitset is more convenient.
#include <bitset>
int i = 5;
bitset<9> bs1 {"10001111"}; // reads the first 9 bits
bitset<9> bs2 {0b1'1000'1111}; // binary literal using digit separator ' for readability
bitset<8*sizeof(int)> bs3 = i; // initalize with int
// some common functions
bs1.all(); // false - not all bits set
bs1.none(); // none of bits set?
bs1.any(); // any bits set?
bs1.test(0); // idx 0 value - 0 from LSD/RHS
bs1.count() // count number of set bits
bs1.flip(0); // flip bit at idx 0
Union and std::variant
A union is a struct in which all members are allocated same address, so that union occupies only as much space as its largest member. Union can only hold a value for one member at a time. But union doesn’t keep track of which kind of value it holds!
union Value {
Node* p;
int i;
}
struct Entry {
string name;
Type t; // custom type to identify if Value is Node pointer or int
Value v;
}variant<A,B,C> is a safer alternative to union. If we try to access variant holding a different type from expected, bad_variant_access is thrown.
std::visit and Overloaded
using Node = variant<Expression, Statement, Declaration, Type>;
// if else check relatively inefficent
void check(Node* p) {
if (holds_alternative<Expression>(*p)) {
Expression& e = get<Expression>(*p);
// ...
} else if (holds_alternative<Statement>(*p)) {
Statement& s = get<Statement>(*p);
// ...
}
}
void check(Node* p) {
std::visit(overloaded {
[](Expression &e) { ... },
[](Statement &s) { ... },
// ...
}, *p);
}
// using std::visit and overloaded class std::optional
If we try to access an optional that does not hold value, the result is undefined and exception is NOT thrown.
optional<int> sum(optional<int> a, optional<int> b) {
return *a+*b; // accessing optional that does not hold value via * (ptr to object)
}
void fn()
{
optional<int> s = sum({}, {});
cout << s.value_or(-1); // cout a random number instead of -1
}
std::any
If we try to access an any holding different type from expected one, bad_any_access is thrown.
any compose(isstream& s) { ... }
auto m = compose(cin);
string & s = any_cast<string>(m);
cout<<s;
Chapter 16: Utilities
Function Adaptation
When passing a function as a function argument, we can consider:
- Use a lambda
- Use
std::mem_fn()to make function object from a member function
void draw_all(vector<Shape*>& v) {
for_each(v.begin(), v.end(), mem_fn(&Shape::draw));
}
// auto f = mem_fn(&Shape::draw)); where f is a functor equivalent to f = [](Shape* p){ p->draw(); };- Define the function to accept std::function. An object of type
functionis a function object.function, being an object, does not participate in overloading
int f1(double);
function<int(double)> fct1{f1}; // initialize to f1
int f2(string);
function fct2{f2}; // fct2's type is deduced from initializer f2, so type is function<int(string)>For a function object which the size is not computed at compile time, free store allocation might occur, which has bad implications to performance critical applications. For C++ 23 solution: move_only_function
Type Functions
A type function is a function that is evaluated at compile time given a type as its argument or returning a type.
constexpr float min = numeric_limits<float>::min();
constexpr int szi = sizeof(int);
// in <type_traits>
bool b = is_arithmetic_v<X>;
using Res = invoke_result_t<decltype(f)>; // Res is int if function f returns an int
// decltype() is also a type function returning the declared type of its argument
// example: priority_queue<tree, vector<tree>, decltype(lambda1)> pq1{lambda1};Concepts are the best type functions. (But most STL as written pre-concepts and must support pre-concept codebases.) Notational conventions _v for type functions that return values, _t for type functions that return types.
Type functions are part of C++ mechanisms for compile-time computation and allow for tight type checking.
Simple type functions that answer fundamental questions about types are type predicates.
template<typename T>
concept Arithemtic = is_arithmetic_v<T>; // is_arithmetic_v type predicate
template<typename T>
concept Class = is_class_v<T> || is_union_v<T>; // unions are classes
template<typename T>
class Smart_pointer {
// ...
T& operator*() const;
T* operator->() const requires Class<T>; // -> is defined if and only if T is a class or union
};
Many type functions return types, often new types they that they compute. Common example is enable_if.
R=enable_if<b, T> // if b is true, R is T, otherwise R is undefined
template<typename T>
struct is_container_type_v {
static const bool value = false;
};
// define a new specialisation
template<typename T>
struct is_container_type_v<vector<T>> {
static const bool value = true;
};
// define a new specialisation
template<typename T>
struct is_container_type_v<set<T>> {
static const bool value = true;
};
// to prevent template ambiguity
template<typename T>
string ToString(const T& x, typename enable_if<!is_container_type_v<T>::value, int>::type* = 0) {
return to_string(x);
}
template<typename T>
string ToString(const T& x, typename enable_if<is_container_type_v<T>::value, int>::type* = 0) { // dummy int* argument is not used
if (x.empty()) return "[]";
string res = "[";
for (const auto& ele : x) {
res.append(ToString(ele));
res.push_back(',');
}
res.back() = ']';
return res;
}
void fn()
{
vector<int> vec{1,2,3,4,5};
cout<<ToString(vec);
}
template<typename T>
concept Class = is_class_v<T> || is_union_v<T>;
template<typename T>
class Smart_pointer {
public:
Smart_pointer(T* r) : ptr{r} {}
T& operator*() { return *ptr; }
typename enable_if<is_class_v<T> || is_union_v<T>, T*>::type operator->() { return ptr; }
// (using concepts) T* operator->() requires Class<T> { return ptr; }
~Smart_pointer() {if (ptr) delete ptr; }
private:
T* ptr;
};
template<typename T, typename U>
struct MyPair {
T first;
U second;
};
void fn()
{
Smart_pointer ptr{new MyPair{1,2}}; // OK: template argument deduction to Smart_pointer<MyPair<int, int>> , but error: Smart_pointer<MyPair>
cout<<ptr->first<<","<<ptr->second; // 1,2
}
source_location
Since C++ 20. Older compilers use macros __FILE__ and __LINE__
void log(const string& mess = "", const source_location loc = source_location::current()) {
cout<<loc.file_name()<<'('<<loc.line()<<':'<<loc.column()<<')'<<loc.function_name()<<": "<<mess;
}
move and forward
Move doesn’t move anything. Instead, it casts its argument to an rvalue reference (argument will not be used again and therefore may be moved). The state of a moved-from object is undefined behaviour. For container (vector/string), the moved-from state will be empty.
When you see std::move, it indicates that the value of the object should not be used afterwards, but you can still assign a new value and continue using it. Thus, std::forward has a single use case: to cast a templated function parameter (inside the function) to the value category (lvalue or rvalue) the caller used to pass it. This allows rvalue arguments to be passed on as rvalues, and lvalues to be passed on as lvalues, a scheme called “perfect forwarding.”
template<typename T, typename ...Args>
unique_ptr<T> custom_make_unique(Args&& ...args) {
return unique_ptr<T>{new T{std::forward<Args>(args)...}}; // allows forwarding rvalue references
};
unique_ptr<pair<int, int>> p = custom_make_unique<pair<int, int>>(5,6);
Exiting a Program (exit vs abort)
exit(x): calls functions registered with atexit() then exit the program with return value x.
abort(): exit the program immediately and unconditionally with a return value indicating unsuccessful termination.
quick_exit(x): calls functions registered with at_quick_exit(); then exit the program with the return value x.
terminate(): call the terminate_handler. Default terminate_handler is abort();
abort() exits your program without calling functions registered using atexit() first, and without calling objects' destructors first. exit() does both before exiting your program, but does not call destructors for automatic objects (An object constructed by explicit or implicit use of a constructor is automatic and will be destroyed at the first opportunity) .
A a;
void test() {
static A b;
A c; // automatic object
exit(0);
}Will destruct a and b properly, but will not call destructors of c. abort() wouldn't call destructors of neither objects.
As this is unfortunate, the C++ Standard describes an alternative mechanism which ensures properly termination:
Objects with automatic storage duration are all destroyed in a program whose function main() contains no automatic objects and executes the call to exit(). Control can be transferred directly to such a main() by throwing an exception that is caught in main().
struct exit_exception {
int c;
exit_exception(int c):c(c) { }
};
int main() {
try {
// put all code in here
} catch(exit_exception& e) {
exit(e.c);
}
}
Instead of calling exit(), arrange that code throw exit_exception(exit_code); instead.
Chapter 17: Numerics
Overview
| numeric limits | static_assert(100000 < numeric_limits<int>::max(), “small ints!”); // numeric_limits is constexpr |
| type aliases | size_t (is alias of the type return by sizeof operator) ptrdiff_t (the type of result of subtracting ptrs) |
| math constants | log2e, log10e, e, pi, ln2 (log(2)), ln10 |
Random Numbers
srand(time(0)); // srand (seed rand) Get different random number each time the program runs
int randomNum = rand() % 101; // Generate a random number between 0 and 100Valarray - Vector Arithmetic
valarray<double> f(valarray<double>& a1, valarray<double>& a2) {
valarray<double> a = a1*3.14+a2/a1; // numeric array operators *,+,/ and =
a2 += a1*3.14;
a = abs(a);
double d = a2[7];
// ...
return a;
}
Chapter 18: Concurrency
Task and threads
Computation that can potentially be executed concurrently with other computations a task. A thread is system level representation of a task in a program. A task is a function or function object. Task is launched upon constructing a thread.
void f(const vector<double>& v, double* res); // function
class F { // function object
public:
F(const vector<double>& vv, double* p) : v{vv}, res{p} { }
void operator()(); // F's call operator
private:
const vector<double>& v; // source of input
const double* res; // target output (sneaky way of returning a result - by passing ptr)
};
void user(vector<double>& vec1, vector<double>& vec2, vector<double>& vec3) {
double res1;
double res2;
double res3;
// f(), F()() and lambda execute in separate threads - tasks are launched
thread t1 {f,cref(vec1), &res1}; // pass const-ref arguments using cref(), ref() for non-const args
thread t2 {F{vec2, &res2}};
thread t3 {[&](){ res3 = g(vec3); }}; // [&] capture local variables by reference
t1.join(); // join before using results (res1, res2, res3)
t2.join();
t3.join();
}
STL provides jthread, RAII by having destructor join().
void user() {
jthread t1 {f};
jthread t2 {F{}};
};
// Joining is done by destructors, so in reverse order of construction. we wait for t2 before t1.Programming concurrent tasks can be tricky. For example, if multiple threads use cout without synchronization, result is unpredictable. Consider one thread use a stream or use osyncstream.
Mutexes and Locks
Mutex (mutual exclusion object) is a key element of general sharing of data between threads. Use of resource handles, like scoped_lock and unique_lock, is far safer and simpler due to RAII.
Deadlock scenario: if thread1 acquires mutex1 and then tries to acquire mutex2 while thread2 acquires mutex2 and then tries to acquire mutex1, neither task will ever proceed further. scoped_lock helps by enabling us to acquire several locks simultaneously, and will only proceed after acquiring all mutexes arguments and will never block (go to sleep when a process is waiting for an event or resource) while holding a mutex.
void f() {
scoped_lock lck{mutex1, mutex2, mutex3}; // acquire all 3 locks
// ... manipulate shared data
} // implicitly release resources via mutex1.unlock(); mutex2.unlock(); mutex3.unlock();
Sharing data among many readers and one writer, we can use shared_mutex
class ThreadSafeCounter {
public:
ThreadSafeCounter() = default;
// using shared mutex, multiple threads can read at same time
unsigned int get() const {
shared_lock lck(mx_);
return value_;
}
// unique_lock on shared_mutex, so only one thread can write at given point in time
void increment() {
unique_lock lck(mx_);
++value_;
}
void reset() {
unique_lock lck(mx_);
value_ = 0;
}
private:
/* The keyword mutable is mainly used to allow a particular data member of const object to be modified.
With your const reference or pointer you are constrained to:
1) only read access for any visible data members
2) permission to call only methods that are marked as const.
The mutable exception makes it so you can now write or set data members that are marked mutable.
hat's the only externally visible difference. */
mutable shared_mutex mx_;
unsigned int value_{};
};
void fn()
{
ThreadSafeCounter counter;
auto increment_and_print = [&counter]()
{
for (int i{}; i != 3; ++i)
{
counter.increment();
std::osyncstream(std::cout)
<< std::this_thread::get_id() << ' ' << counter.get() << '\n';
}
};
std::jthread thread1(increment_and_print);
std::jthread thread2(increment_and_print);
}
Communicating (i.e, message) using external events is provided by condition_variable.
class Message { ... } // object to be communicated
queue<Message> mqueue;
conditon_variable mcond;
mutex mmutex; // for synchronising access to mcond
void consumer() {
while (true) {
unique_lock lck{mmutex};
mcond.wait(lck, []{ return !mqueue.empty(); });
// release mmutex and wait reacquire mmutex on wakeup. Wakeup condition: !mqueue.empty()
auto m = mqueue.front();
mqueue.pop();
lck.unlock(); // release mmutex
// ... process m
}
}
void producer() {
while (true) {
Message m;
// ... fill message
scoped_lock lck{mmutex};
mqueue.push(m);
mcond.notify_one(); // notify and then mmutex (as it is end of scope)
}
}We use unique_lock for consumer for 2 reasons:
- Pass
lcktoconditon_variablewait().scoped_lockcannot be moved, butunique_lockcan.
unique_lockhaslock()andunlock(), but‘class std::scoped_lock’ has no member named ‘unlock’
Atomics
Each instantiation and full specialization of the std::atomic template defines an atomic type. If one thread writes to an atomic object while another thread reads from it, the behavior is well-defined (see memory model for details on data races).
Well-defined means that accesses to atomic objects may establish inter-thread synchronization and order non-atomic memory accesses as specified by std::memory_order.
std::atomic is neither copyable nor movable.
future, promise and packaged_task
A packaged_task gets a future into the task that need a result and the corresponding promise into the thread that should produce the result. A packaged_task cannot be copied (since it itself is a resource handle, it owns its promise), only can be moved.
double accum(vector<double>::iterator beg, vector<double>::iterator end, double init) {
return accumulate(&*beg,&*end,init);
}
double comp2(vector<double>& v) {
packaged_task pt0{accum};
packaged_task pt1{accum};
future<double> f0 {pt0.get_future()};
future<double> f1 {pt1.get_future()};
double* first = &v[0];
thread t1{move(pt0),first,first+v.size()/2,0};
thread t2{move(pt1),first+v.size()/2,first+v.size(),0};
return f0.get()+f1.get();
}
async()
The function template std::async runs the function f asynchronously (potentially in a separate thread which might be a part of a thread pool) and returns a std::future that will eventually hold the result of that function call.
Limitation: Don’t even think of using async() for tasks that shares resources and hence need locking. With async(), system decides number of threads to use.
auto f0 = async(accum, first,first+v.size()/2,0);
auto f1 = async(accum,first+v.size()/2,first+v.size(),0);
return f0.get() + f1.get();
Stopping a thread
Thread can own resources that must be released (locks, sub-threads, db connections). STL provides to proper clean up with stop_token. (Since C++ 20)
#include <iostream>
#include <thread>
using namespace std::literals::chrono_literals;
void f(std::stop_token stop_token, int value)
{
while (!stop_token.stop_requested())
{
std::cout << value++ << ' ' << std::flush;
std::this_thread::sleep_for(200ms);
}
std::cout << std::endl;
}
int main()
{
std::jthread thread(f, 5); // prints 5 6 7 8... for approximately 3 seconds
std::this_thread::sleep_for(3s);
// The destructor of jthread calls request_stop() and join().
}
Coroutines
A coroutine is a function that maintains its state between calls. In that, it’s a bit like a function object, but saving and restoring its state between calls. If you need 1000 tasks, why not threads for such applications? A thread requires a megabyte or two (mostly for its stack), a coroutine often only a couple of dozen bytes. Moreover, context-switching between coroutines is far faster than between threads/processes.
Coroutine state is allocated dynamically via non-array operator new. When the coroutine state is destroyed either because it terminated via co_return or uncaught exception, or because it was destroyed via its handle, it does the following:
- calls the destructor of the promise object.
- calls the destructors of the function parameter copies.
- calls operator delete to free the memory used by the coroutine state.
- transfers execution back to the caller/resumer.
The call to operator new can be optimized out (even if custom allocator is used) if
- The lifetime of the coroutine state is strictly nested within the lifetime of the caller, and
- the size of coroutine frame is known at the call site.
In that case, coroutine state is embedded in the caller's stack frame (if the caller is an ordinary function) or coroutine state (if the caller is a coroutine).
A function is a coroutine if its definition contains any of the following:
- the
co_awaitexpression — to suspend execution until resumed
task<> tcp_echo_server()
{
char data[1024];
while (true)
{
std::size_t n = co_await socket.async_read_some(buffer(data));
co_await async_write(socket, buffer(data, n));
}
}- the
co_yieldexpression — to suspend execution returning a value
generator<unsigned int> iota(unsigned int n = 0)
{
while (true)
co_yield n++;
}`- the
co_returnstatement — to complete execution returning a value
Coroutines cannot use variadic arguments, plain return statements, or placeholder return types (auto or Concept).
Consteval functions, constexpr functions, constructors, destructors, and the main function cannot be coroutines.
Chapter 19: History and Compatibility
Struct Alignment
Alignment matters not only for performance, but also for correctness. Some architectures will fail with an processor trap if the data is not aligned correctly, or access the wrong memory location. On others, access to unaligned variables is broken into multiple accesses and bitshifts (often inside the hardware, sometimes by OS trap handler), losing atomicity.
The advice to sort members in descending order of size (biggest to smallest) is for optimal packing / minimum space wasted by padding, not for alignment or speed. Members will be correctly aligned no matter what order you list them in, unless you request non-conformant layout using specialized pragmas (i.e. the non-portable #pragma pack) or keywords. Although total structure size is affected by padding and also affects speed, often there is another ordering that is optimal.
For best performance, you should try to get members which are used together into the same cache line, and members that are accessed by different threads into different cache lines. Sometimes that means a lot of padding to get a cross-thread shared variable alone in its own cache line. But that's better than taking a performance hit from false sharing.
void*
void* cannot be used as RHS operand of an assignment in initialization of a variable of any pointer type.
char ch;
void* pv = &ch; // OK
int* pi = pv; // Error: invalid conversion from ‘void*’ to ‘int*’
extern
It is useful when you share a variable between a few modules. You define it in one module, and use extern in the others. When the linker sees extern before a global variable declaration, it looks for the definition in another translation unit. Declarations of non-const variables at global scope are external by default. Only apply extern to the declarations that don't provide the definition.
For example:
in file1.cpp:
int global_int = 1;in file2.cpp:
extern int global_int;
//in some function
cout << "global_int = " << global_int;